The plan
One of Redpill Linpro’s customers - had parts of their web presence managed by another provider - “P”. The customer wanted to migrate the server operations to Redpill Linpro (“RL”), including moving their Elasticsearch cluster to Redpill Linpro’s Elasticsearch offering, preferably without downtime. While exporting and importing by using snapshots was an option, the better option would be a live migration.
 A really useful Elasticsearch feature is the capability of adding and
removing cluster nodes and letting the cluster move the data
seamlessly between them. We planned to expand the
existing three-node cluster with three more nodes on Redpill Linpro’s
side, creating a six-node cluster spanning the old and new
provider. That way the full cluster would be available throughout the
migration process, in that the servers and services running at P
would still be able to access the cluster while it was simultaneously
available to the servers being set up in Redpill Linpro’s
environment. When all surrounding services were successfully
migrated, we’d evict the P nodes from the Elasticsearch cluster.
A really useful Elasticsearch feature is the capability of adding and
removing cluster nodes and letting the cluster move the data
seamlessly between them. We planned to expand the
existing three-node cluster with three more nodes on Redpill Linpro’s
side, creating a six-node cluster spanning the old and new
provider. That way the full cluster would be available throughout the
migration process, in that the servers and services running at P
would still be able to access the cluster while it was simultaneously
available to the servers being set up in Redpill Linpro’s
environment. When all surrounding services were successfully
migrated, we’d evict the P nodes from the Elasticsearch cluster.
A tale of two environments
From their office network, the customer had SSH access to the original Elasticsearch cluster, including sudo privileges. The Elasticsearch servers themselves were configured with RFC1918 private IPv4 addresses but had outbound SSH access, although behind NAT. There was no inbound access, and since the customer was leaving their old provider we didn’t want to bother the provider with configuring site-to-site VPN.
On the Redpill Linpro side, Elasticsearch is running in our OpenStack based Nordic Cloud. Customer access takes place on a tenant accessible network for accessing the cluster, while internal cluster communication, referred to as “transport” in Elasticsearch naming, happens on an internal network not available to the customer. Both networks are configured with IPv4 addresses in the RFC1918 private IP ranges, dual-stacked with regular IPv6 addresses. If the customer needs access to the Elasticsearch environment, an official “floating” IPv4 address is mapped to a virtual IP moving between the cluster nodes. Direct IPv6 access to the tenant side may also be allowed on demand.
The obstacles
To successfully upscale and downscale a cluster as planned, all nodes must see all nodes (full mesh). On each side of the gap that’s no problem. Between them, however, RL nodes wouldn’t be able to reach P nodes due to NAT and outbound-only access on P’s side.
Similarly, P nodes wouldn’t be able to correctly access RL nodes because a) the only available external interface is a single virtual IP moving between the nodes, and b) the transport interface isn’t exposed on the customer-facing network anyways.
Rewiring the Elasticsearch network
In addition to the built-in floating address mapped to a moving IP in the tenant network, we allocated floating addresses to each node’s unique tenant address. Furthermore, we temporarily reconfigured the Elasticsearch configuration to allow for intra-cluster (i.e. transport) communication on all interfaces.
This part could have solved the issue of P nodes reaching RL nodes, if it hadn’t been for that pesky little problem that the nodes announce their internal names or IPs when handshaking.
Completing the network puzzle
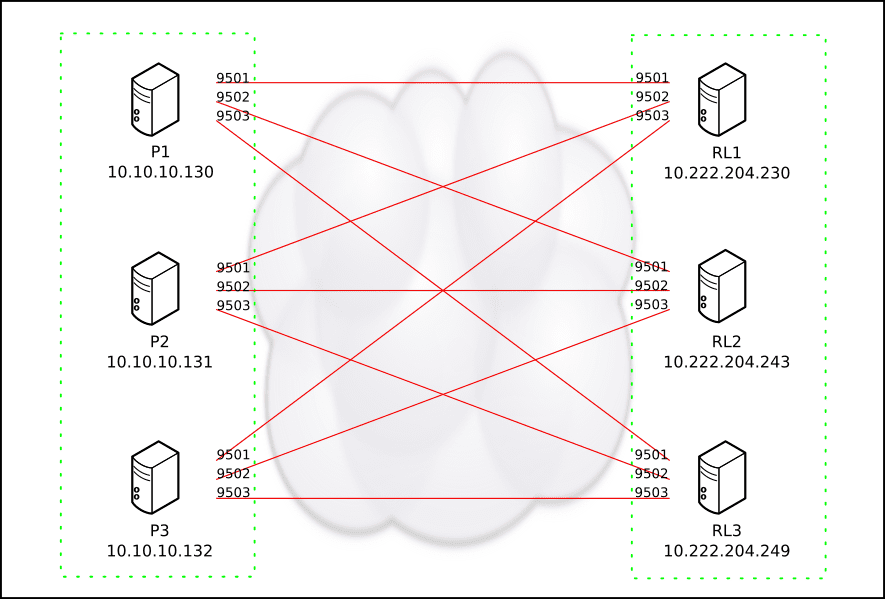
After re-configuring the networking, we set up key-based SSH tunneling through connections from each of the P nodes to each of the three RL nodes. To ensure reconnects if any network issues should occur, we used AutoSSH. Both forward and reverse tunnels were configured, providing access from P nodes to RL nodes as well as return access from RL nodes to P nodes, all on local/RFC1918 addresses.
For instance, this is the AutoSSH configuration running on P1, providing forward and reverse tunnels between P1 and RL1/2/3:
# P1 config
/usr/bin/autossh -M0 -q -N -f \
-o "ServerAliveInterval 60" \
-o "ServerAliveCountMax 3" \
-L 9501:127.0.0.1:9300 \ # forward tunnel
-R 9501:10.10.10.130:9300 \ # reverse tunnel
customer@IP1 # official IP RL1
/usr/bin/autossh -M0 -q -N -f \
-o "ServerAliveInterval 60" \
-o "ServerAliveCountMax 3" \
-L 9502:127.0.0.1:9300 \ # forward tunnel
-R 9501:10.10.10.130:9300 \ # reverse tunnel
customer@IP2 # official IP RL2
/usr/bin/autossh -M0 -q -N -f \
-o "ServerAliveInterval 60" \
-o "ServerAliveCountMax 3" \
-L 9503:127.0.0.1:9300 \ # forward tunnel
-R 9501:10.10.10.130:9300 \ # reverse tunnel
customer@IP3 # official IP RL3
The above configuration opens three listening ports on P1, namely 9501 towards RL1, 9502 towards RL2, and 9503 towards RL3. Simultaneously, the port 9501 is opened on each RL node back to the originating node P1.
This is only half of it, though. To properly send the transport communication through the tunnel, we’re also using iptables to hijack and reroute the traffic.
# Force traffic to RL1 port 9300 into port 9501
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d **RL1** -j DNAT \
--to-destination 127.0.0.1:9501
# Force traffic to RL2 port 9300 into port 9502
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d **RL2** -j DNAT \
--to-destination 127.0.0.1:9502
# Force traffic to RL3 port 9300 into port 9503
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d RL3 -j DNAT \
--to-destination 127.0.0.1:9503
SSH tunnels are only initiated from the P nodes, but the iptables rerouting must happen on RL nodes as well. Below is an example from the RL1 node.
# Force traffic to P1 port 9300 into port 9501
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d P1 -j DNAT \
--to-destination 127.0.0.1:9501
# Force traffic to P2 port 9300 into port 9502
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d P2 -j DNAT \
--to-destination 127.0.0.1:9502
# Force traffic to P3 port 9300 into port 9503
/sbin/iptables -t nat -A OUTPUT \
-p tcp --dport 9300 -d P3 -j DNAT \
--to-destination 127.0.0.1:9503
After all SSH connections were up and running and iptables commands had been run on all six nodes, each node could successfully connect to any other node as if they all were in the same network.
Migration time
With all port forwardings in place, all nodes could reach each other in a full mesh. By adding the P nodes as existing master nodes to each RL node, the RL nodes were started and successfully joined the cluster. Initially they were added as coordinating nodes so they wouldn’t start migrating data. After confirming that all six nodes formed a full cluster the RL nodes were promoted to data and master nodes. At this stage the services running in the old environment were still feeding data to the Elasticsearch cluster, and the services being established on the Redpill Linpro side were also able to communicate with the cluster via the Elasticsearch nodes local to them.
During the migration, we had to make sure the Elasticsearch cluster didn’t break down and/or lose data if something should happen to the connections between P and RL. By introducing shard awareness in Elasticsearch’s configuration, the cluster was forced to keep primary shards on one of the sites and replica shards on the other. If a split-brain situation should occur, each side would hold a full set of data.
Closure
When all services were successfully migrated to the RL environment, it was time to detach and shut down the old Elasticsearch nodes. By using the exclude_ip setting the cluster drained and evicted the old nodes, one by one. During the last phase of this transition we also disabled the site awareness, otherwise the cluster would have complained that the unavailability of the P nodes blocked a responsible allocation of indexes and shards.
